前端优化主要方法记住这篇博文-前端性能优化
优化方法脑图:
大图地址:http://naotu.baidu.com/file/535e0e918b3946c04cf87a1ebf32f29d
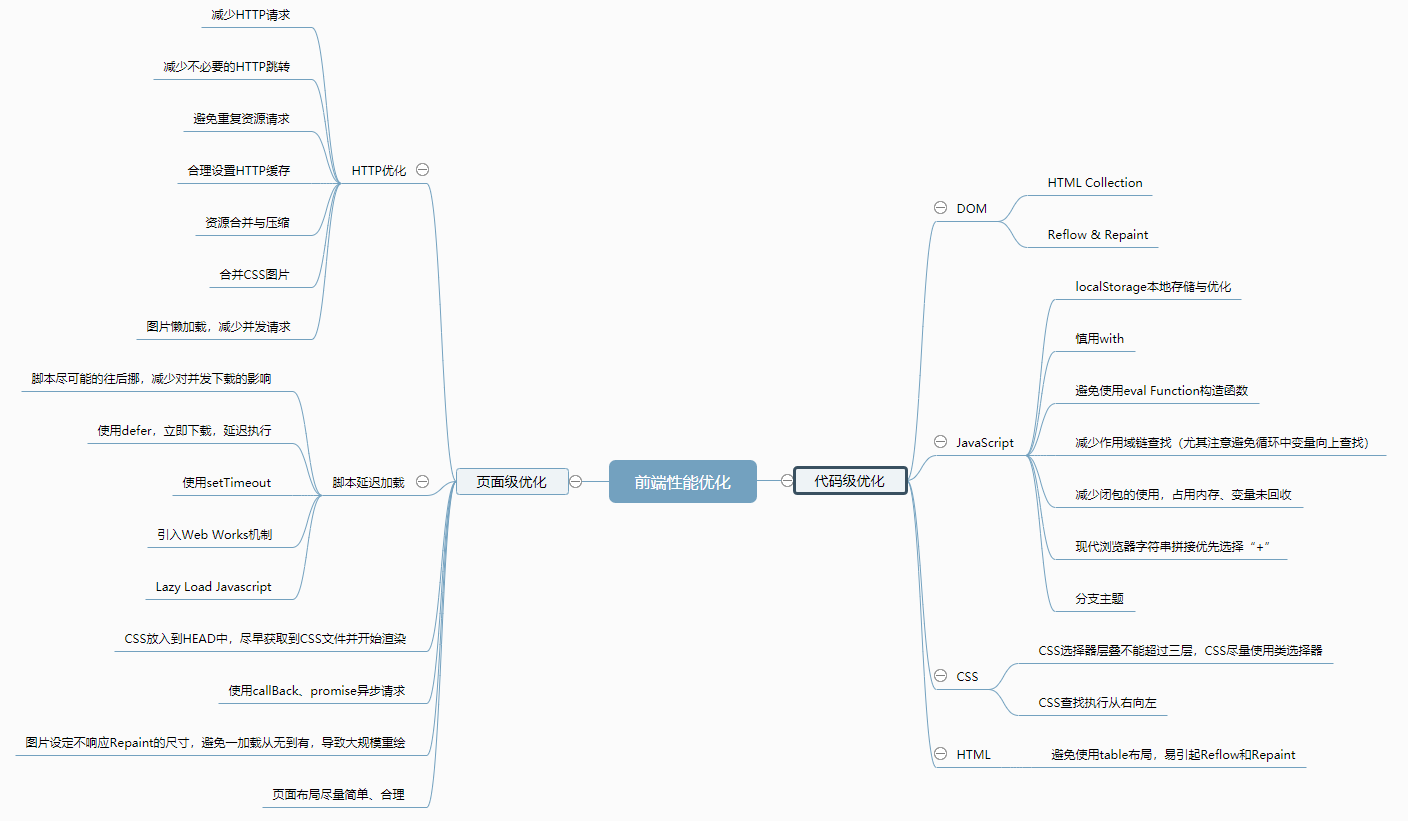
以下为后续看到优化方法的补充:
前端优化主要方法记住这篇博文-前端性能优化
优化方法脑图:
大图地址:http://naotu.baidu.com/file/535e0e918b3946c04cf87a1ebf32f29d
以下为后续看到优化方法的补充:
前言:以前刚学JS的时候,一直觉得前端不怎么需要算法,就是单纯的实现业务功能,现在想想那时候的想法多少天真,可以说用幼稚来形容了。作为一个合格的程序猿,怎么可能不搞算法,前端的算法不会太复杂,一般都是一些比较简单的算法,对照剑指offer,将里面的算法重新实战一遍,代码位置在另一个仓库Offer
题目:在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
思路:二维数组是有规律的,按照横纵展开,向右向下递增。选取数组右上角的数字,如果该数字等于要查找的数组,则结束。如果大于要查找的数字,则该列都大于要查找的数字,剔除该列,向左移动一列继续查找;如果小于要查找的数字,则该行都小于要查找的数字,剔除该行,向下移动一行继续查找;直到查找到该数字或者查找到左下角还没有匹配,则返回没有匹配。
代码:github
1 | function find(array, target) { |
题目:请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
思路:当然是直接用正则匹配然后使用replace替换就好了。
代码:
1 | function replaceSpace(str) { |
题目:输入一个链表,从尾到头打印链表每个节点的值。
不懂链表的可以参考《学习JavaScript的数据结构与算法》
思路:先将链表每个结点的值存入数组中,然后通过数组的reverse方法,即可从尾到头打印
代码:Github
1 | function printLinkedList(head) { |
题目:输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
思路:
代码:Github
题目:用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型
思路:栈的操作是后入先出(LIFO),队列的操作是先入先出(FIFO)
代码:Github
1 | let arr1 = [], arr2 = [], result = []; |
题目:把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。 输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。 NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
思路:其实剑指Offer中想要表达的是一种寻找数组最小值的二分查找方法,旋转之后原数组分为两个部分,[3,4,5,1,2],前面的部分最小的数肯定大于或等于后面部分最大的数,通过这一点可以节省遍历,典型的二分法。
代码:Github
1 | function rotate(arr) { |
题目:大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。n<=39
思路:传统思路是使用递归,这种方法简单直接,但是会有一个问题,存在严重的效率问题,很多的重复计算,因此,剑指Offer提出一种优化方法,使用内存记录之前的计算结果,从0 ,1 ,2 开始一直到n,计算过的值被记录下来,就不用再计算了。大大的节省了时间。
代码:Github
1 | function fibonacci(n) { |
题目:一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
思路:其实就是斐波那契函数的应用,如果n=1则只有一种,如果n=2则有两种,如果n=3,则有前两种之和,记一个函数f(n),则跳法为f(n-1)+f(n-2)
代码:Github
1 | function fibonacci(n) { |
题目:一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
思路:其实就是斐波那契函数的应用,如果n=1则只有一种,如果n=2则有两种,如果n=3,则有前两种之和在加上自己跳n阶的一种,记一个函数f(n),则跳法为f(n-1)+f(n-2)+…+f(1)+1
代码:Github1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function fibonacci(n) {
var arr = [1, 2];
if (n === 1 || n === 2)
return arr[n - 1];
else {
var result = 0;
for (var i = 3; i <= n; i++) {
result = 1 + arr.reduce(function (total, currentValue) {
return total + currentValue;
});
arr.push(result);
}
return result;
}
}
题目:我们可以用21的小矩形横着或者竖着去覆盖更大的矩形。请问用n个21的小矩形无重叠地覆盖一个2*n的大矩形,总共有多少种方法?
思路:其实就是斐波那契函数的应用,注意题目中是无重叠,如果n=1则只有一种,n=2时则有2种,
n=3时,左上角可以横着放也可以竖着放,竖着放的话,右边剩下两列,刚好是f(2)的情况,当横着放的时候,左下角必须横放一个,右边就剩下一列,f(1),则有f(2)+f(1)种,
因此推导f(n)= f(n-1)+f(n-2)
代码:Github1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function rectCover(number) {
// write code here
var n = number;
var arr = [1, 2];
var result = 0;
if (n === 1 || n === 2)
return arr[n - 1];
else {
for (var i = 3; i <= n; i++) {
result = arr[arr.length - 1] + arr[arr.length - 2];
arr.push(result);
}
return result
}
}
题目:输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
思路:
代码:Github
###
题目:
思路:
代码:Github
###
题目:
思路:
代码:Github
前言:尝试自己根据思路去使用js实现的算法,发现对于算法有这么几个问题:
数组去重的几种方法请参照数组操作方法
整理前:
1 | 111.232.213 ascqwdwd |
整理后:
1 | '111.232.213': [ 'ascqwdwd', 'qwdqwdqw' ], |
对于求质数,和判断一个数是不是质数,原理是一样,区别在于求质数是对一群数进行判断,复杂度提高,如果只是判断一个数是不是质数,不要考虑复杂度,直接从2到这个数的平方根开始循环看能不能整除。
对于求多少以内的质数,也可以这样,但是这样的时间复杂度就提高了,网上有说几种不同的境界,这里就不介绍,我才用的筛选法,很明显,对于明显不是质数的数,没有做运算,节省的时间。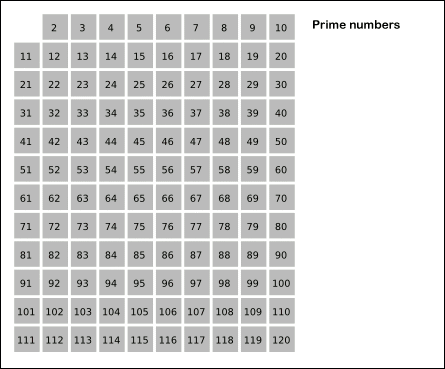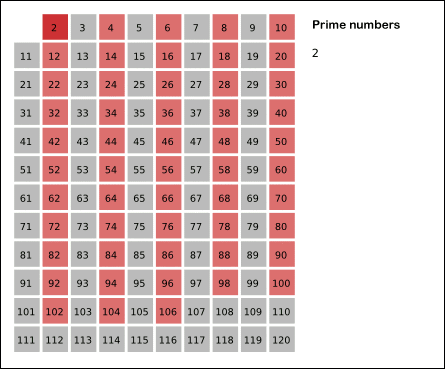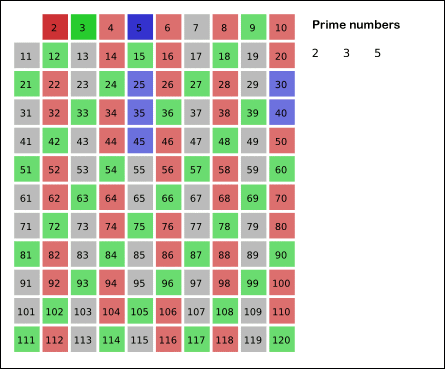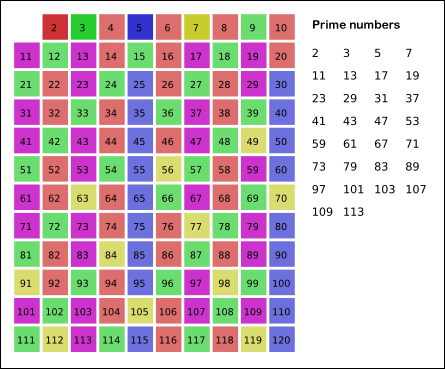
1 | /** 求num中所有质数 |
1 | function exchange(a,b){ |
1 | function maxDiff(array) { |
6、
下面表达式输出的结果为:
1 | for(var i=1;i<4;i++){ |
因为在表达式中定义的var i是全局作用域变量,任何一个地方都可以访问到,并且一定注意,在for循环内,如果都是同步执行的话,则i的值为3,但是如果是类似异步的,for执行完毕之后为i为4,所以所有i的值都为4.
先看一段代码:
1 | function (){ ... }(); |
执行结果为: SyntaxError: Unexpected token (,为什么会有这个错误呢?
要理解两个概念
函数声明
1 | function name([param[, param[, ... param]]]) { |
函数表达式
1 | //一个匿名函数的函数表达式,被赋值给变量f2: |
1 | var f2 = function() { |
所以我们来看之前报错的原因,这是一个函数声明,后面再接一个() ,js引擎看到function关键字之后,认为后面跟的是函数定义语句,不应该以圆括号结尾,解决这个问题就是让引擎知道,圆括号前面的部分不是函数定义语句,而是一个表达式,可以对此进行运算。改写成这样。
1 | (function(){ /* code */ }()); |
有时候看到这样的一种形式,括号中传递一个参数。
1 | (function (p) { return p})(parameter); |
立即 执行的括号中传入了一个参数,执行的过程中此参数就是函数传入的参数。
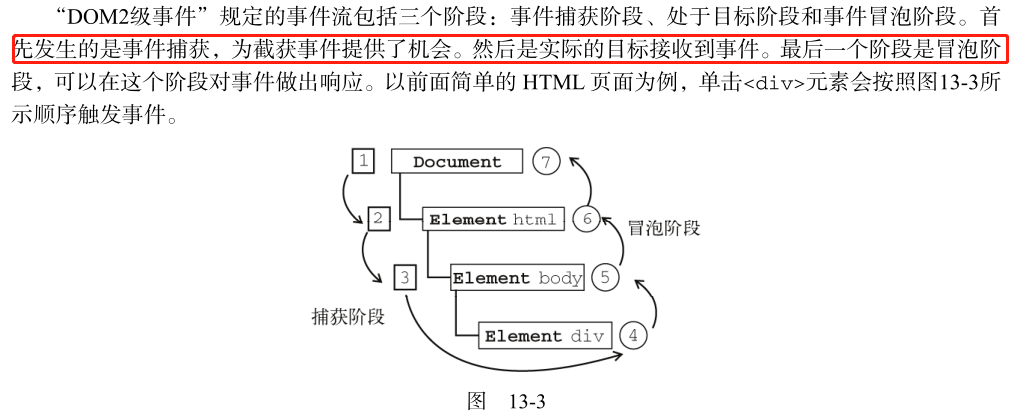
事件绑定后,检测顺序就会从被绑定的DOM下滑到触发的元素,再冒泡会绑定的DOM上。也就是说,如果你监听了一个DOM节点,那也就等于你监听了其所有的后代节点。
代理的意思就是只监听父节点的事件触发,以来代理对其后代节点的监听,而你需要做的只是通过currentTarget属性得到触发元素并作出回应。
使用事件代理意味着你可以节省大量重复的事件监听,以减少浏览器资源消耗。还有一个好处就是让HTML独立起来,比如之后还有要加子元素的需求,也不需要再为其单独加事件监听了。
DOM0级事件处理就是讲一个函数赋值给一个事件处理程序属性
1 | btn.onclick=function (){} |
DOM2级事件处理程序,这里因为历史原因,IE的事件处理操作API名称和常规的不太一样,所以,一般需要考虑到浏览器兼容,高程上给出了一个扩浏览器的EventUtil对象,会检测是是否支持DOM2级事件处理,以及IE下的情况。优先推荐。
注意 :addEventListener()/removeEventListener()最后一个参数为boolean值,true表示在捕获阶段调用事件处理函数,false表示在冒泡阶段处理。
IE下的attachEvent() detachEvent()没有这个布尔值,因为早期IE只支持冒泡,所以IE处理默认冒泡。
1 | /** DOM2级事件处理程序 浏览器兼容 |
在触发 DOM 上的某个事件时,会产生一个事件对象 event ,这个对象中包含着所有与事件有关的信息。包括导致事件的元素、事件的类型以及其他与特定事件相关的信息。例如,鼠标操作导致的事件对象中,会包含鼠标位置的信息,而键盘操作导致的事件对象中,会包含与按下的键有关的信息。所有浏览器都支持 event 对象,但支持方式不同。
当然,在事件对象中IE也有不一样的地方。后面再区别,先看DOM2级事件对象。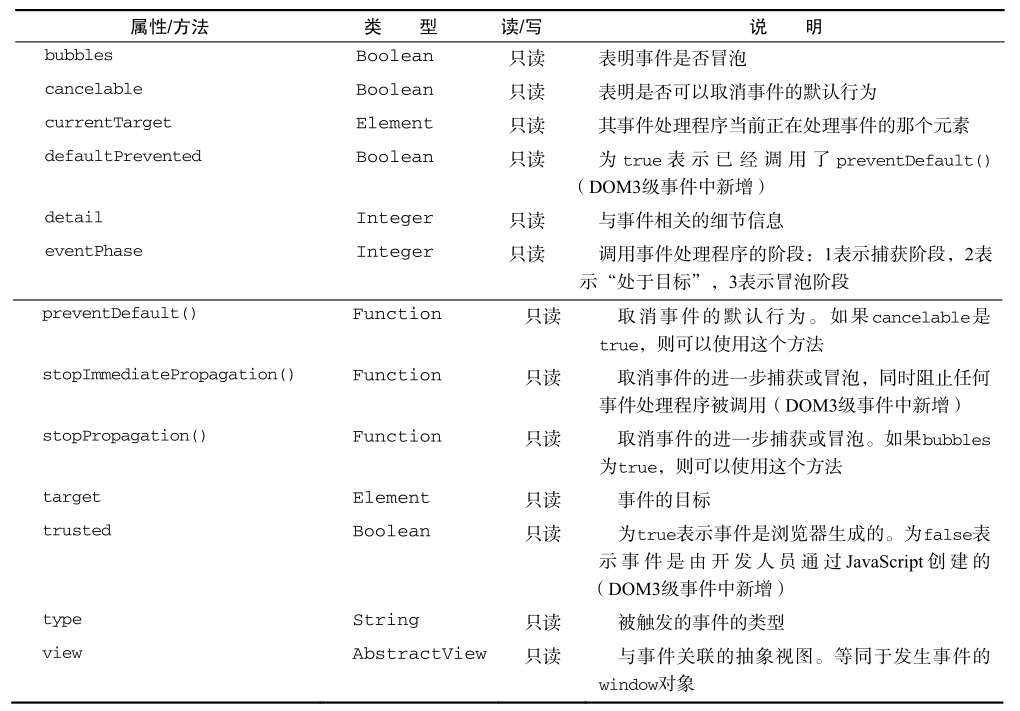
在事件处理程序内部,对象 this 始终等于 currentTarget 的值,而 target 则只包含事件的实际目标。如果直接将事件处理程序指定给了目标元素,则 this 、 currentTarget 和 target 包含相同的值。。如果事件处理程序存在于按钮的父节点中(例如 document.body ),那么这些值是不相同的。


这里面主要记住UI事件,大部分是window对象相关。

在 JavaScript 中,添加到页面上的事件处理程序数量将直接关系到页面的整体运行性能。导致这一问题的原因是多方面的。首先,每个函数都是对象,都会占用内存;内存中的对象越多,性能就越差。其次,必须事先指定所有事件处理程序而导致的 DOM访问次数,会延迟整个页面的交互就绪时间。当然最直接的就是减少页面中事件处理程序。
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。一个典型的应用就是比如有一批列表,给每一个列表都添加一个事件处理程序,则内存占用比较大,然后操作也比较复杂,如果在DOM中尽量高一层级上添加一个事件处理程序,利用事件冒泡,可以让每一个列表都可以获取到事件处理。这种技术对用户最终的结果与之前的方法差不多,但是需要的内存更少。
使用事件委托技术,与传统方法相比较,有如下优势:

内存中保留着那些过时不用的“空事件处理程序”,也是造成Web应用程序内存和性能问题的主要原因。两种典型的情况会造成“空事件处理程序占用内存”的问题:
一般使用手工移除事件处理程序,btn.onclick=null;,然后再设置innerHTML。
一般来说,最好的做法是在页面卸载之前,先通过onunload事件处理程序移除所有事件处理程序。
说到 这里,就又可以看到事件委托技术的优势,如果事件追踪的越少,越容易移除。
mouseover与mouseenter
不论鼠标指针穿过被选元素或其子元素,都会触发 mouseover 事件。
只有在鼠标指针穿过被选元素时,才会触发 mouseenter 事件。
mouseout与mouseleave
不论鼠标指针离开被选元素还是任何子元素,都会触发 mouseout 事件。
只有在鼠标指针离开被选元素时,才会触发 mouseleave 事件。
递归函数是在一个函数通过名字调用自身的情况下构成的。
1 | function factorial(num){ |
这是一个经典的递归阶乘函数。虽然这个函数表面看来没什么问题,但下面的代码却可能导致它出错。
1 | var anotherFactorial = factorial; |
原始函数中有对factorial的引用,将factorial=null后factorial被销毁了,所以执行这个引用后找不到。
arguments.callee稳妥的递归用法使用arguments.callee ,arguments是一个对应于传递给函数的参数的类数组对象,arguments.callee指向正在执行的函数指针。
1 | function factorial(num){ |
但是在严格模式下,不能访问arguments.callee ,使用命名函数表达式实现。
1 | var factorial = (function f(num){ |
以上代码创建了一个名为 f() 的命名函数表达式,然后将它赋值给变量 factorial 。即便把函数赋值给了另一个变量,函数的名字 f 仍然有效,所以递归调用照样能正确完成。这种方式在严格模式和非严格模式下都行得通。
关于正则表达式的匹配,一开始觉得很复杂,主要是因为表达式看不懂,不知道什么是匹配符,限定符,操作符,其实使用过后才发现,正则表达其实是比较简单的,具体的参考下面一篇博文,《JavaScript学习总结(八)正则表达式》里面对于概念的讲解比较详细,正则的使用主要看自己怎么去组合,想要匹配什么样的内容,很多时候,我们要用到的正则匹配,其实网上都有比较全的正则表达式,直接搜索就可以获取到。
充分利用网上的资源才是正确学习正则的途径。
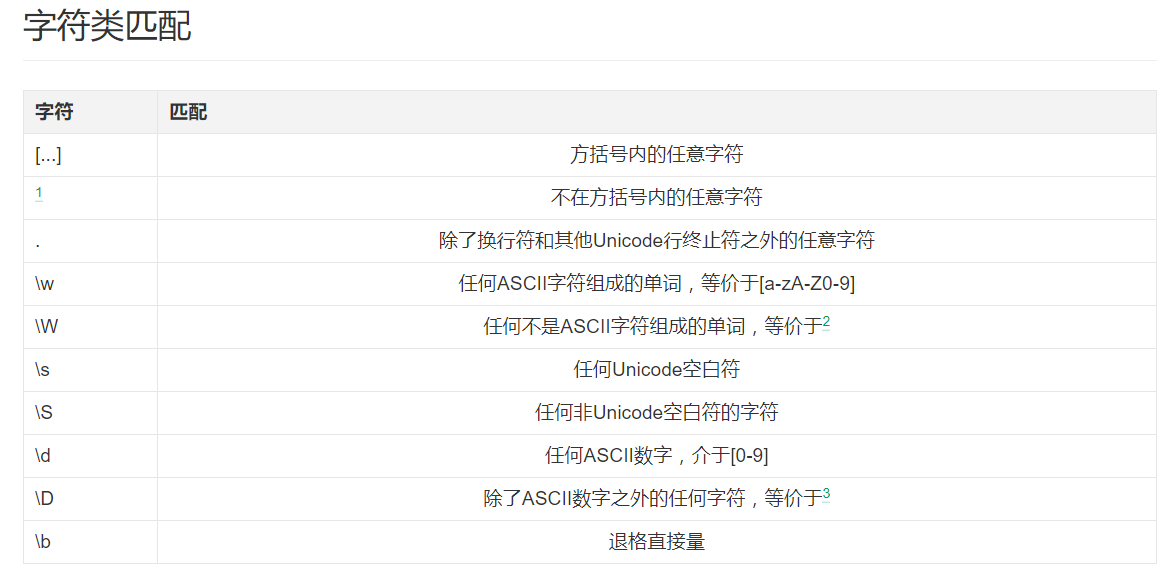
我对于正则的害怕主要是因为记不住正则表达式中特殊字符,MDN有一张表格,很完整很权威,对照这张表格就可以的。要求看到特殊字符就知道是什么意思。
注意正则有一些字符类匹配,很多时候大家都是使用字符类匹配。这个要记住。
 重复匹配符也要注意,这个也要记住,一看就能知道表达的匹配范围。
重复匹配符也要注意,这个也要记住,一看就能知道表达的匹配范围。
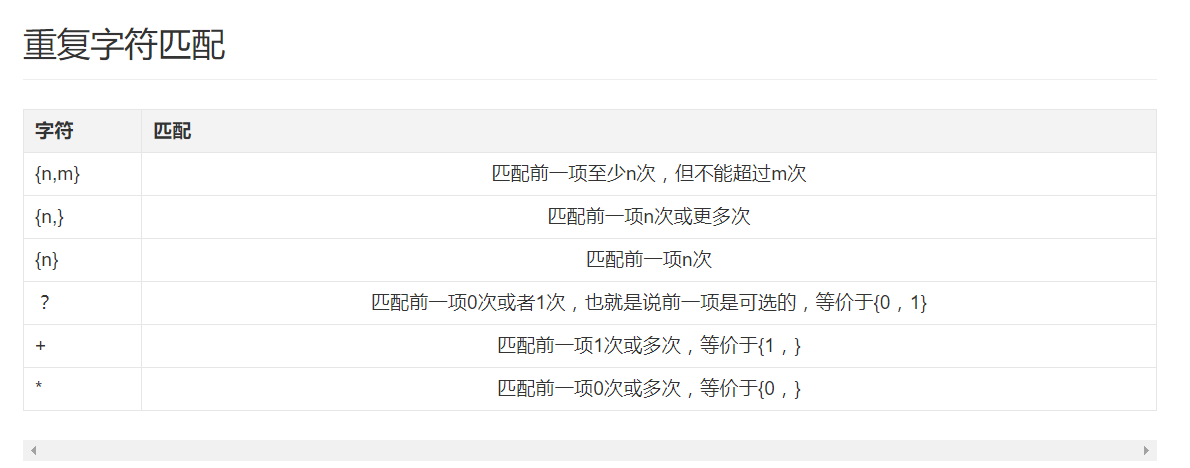
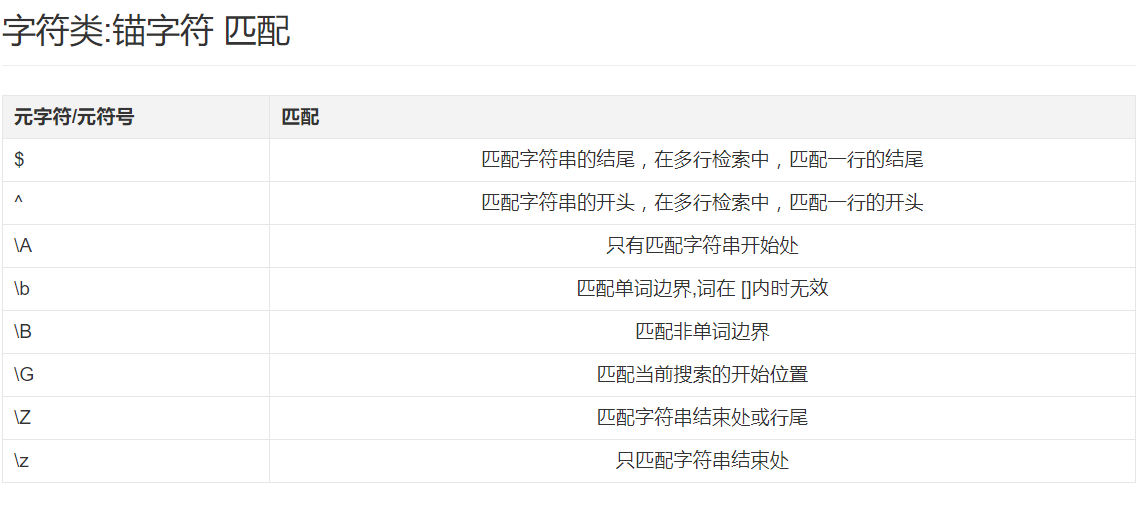 其他的东西就直接在博文上看就可以了。
其他的东西就直接在博文上看就可以了。
下面有一个导图,记住这个导图你就理解了。
1 | 'usestrict'; |
关于这个时间格式化代码,这段厉害就厉害在于,正则表达式应用的非常炉火纯青。尤其replace那一段,使用捕获括号匹配字符串并记住字符串,用$1表示记住的第一个匹配对象,后面替换也很巧妙,设定好位数,然后字符串拼接,最重要的一步,再使用substr截取字符串,一般情况下我想的就是拼凑,先删都拼,比较好的做法是先拼后删。
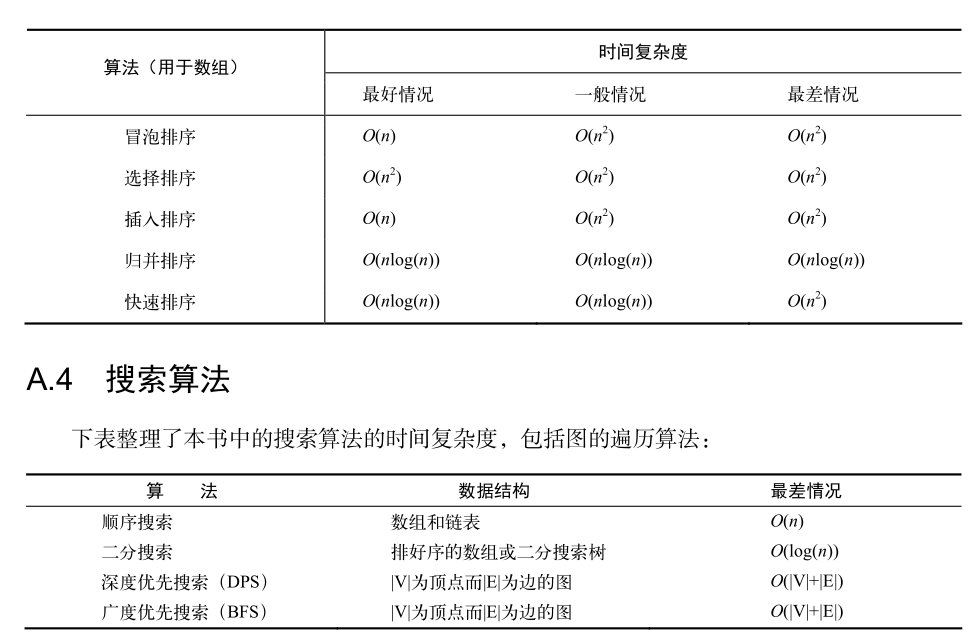
以前对于排序,只知道冒泡排序,了解一点快速排序,一直是我的弱点,今天是时候好好攻克一下了
参考:JS中可能用得到的全部的排序算法
冒泡排序需要两个嵌套的循环. 其中, 外层循环移动游标; 内层循环遍历游标及之后(或之前)的元素, 通过两两交换的方式, 每次只确保该内循环结束位置排序正确, 然后内层循环周期结束, 交由外层循环往后(或前)移动游标, 随即开始下一轮内层循环, 以此类推, 直至循环结束.
1 | // 交换下标a、b对应的数组数值,此方法抽离处理,后面直接使用,不做说明 |
1 | function sort(array) { |

双向冒泡排序是冒泡排序的一个简易升级版, 又称鸡尾酒排序. 冒泡排序是从低到高(或者从高到低)单向排序, 双向冒泡排序顾名思义就是从两个方向分别排序(通常, 先从低到高, 然后从高到低). 因此它比冒泡排序性能稍好一些.
1 | function sort(array) { |
从算法逻辑上看, 选择排序是一种简单且直观的排序算法. 它也是两层循环. 内层循环就像工人一样, 它是真正做事情的, 内层循环每执行一遍, 将选出本次待排序的元素中最小(或最大)的一个, 存放在数组的起始位置. 而 外层循环则像老板一样, 它告诉内层循环你需要不停的工作, 直到工作完成(也就是全部的元素排序完成).
Tips
: 选择排序每次交换的元素都有可能不是相邻的, 因此它有可能打破原来值为相同的元素之间的顺序. 比如数组[2,2,1,3], 正向排序时, 第一个数字2将与数字1交换, 那么两个数字2之间的顺序将和原来的顺序不一致,虽然它们的值相同, 但它们相对的顺序却发生了变化. 我们将这种现象称作不稳定性.
1 | /** 3、选择排序 **/ |
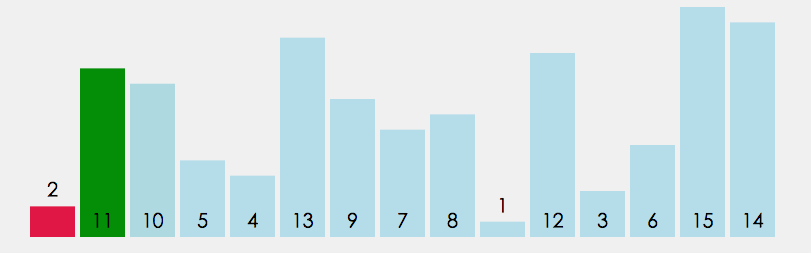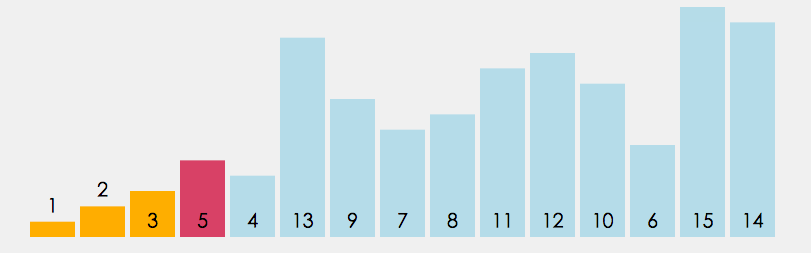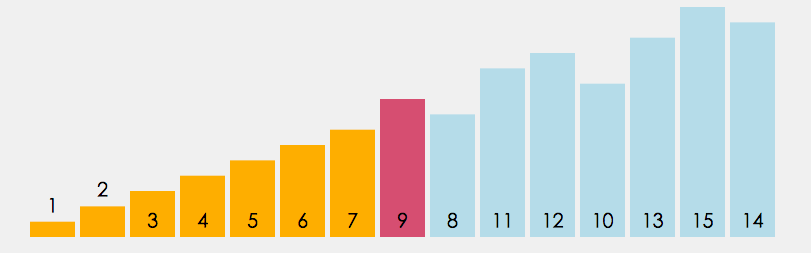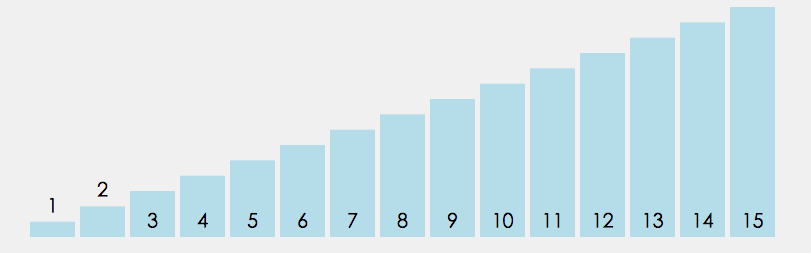

插入排序的设计初衷是往有序的数组中快速插入一个新的元素. 它的算法思想是: 把要排序的数组分为了两个部分, 一部分是数组的全部元素(除去待插入的元素), 另一部分是待插入的元素; 先将第一部分排序完成, 然后再插入这个元素. 其中第一部分的排序也是通过再次拆分为两部分来进行的.
插入排序由于操作不尽相同, 可分为 直接插入排序 , 折半插入排序(又称二分插入排序), 链表插入排序 , 希尔排序 .
它的基本思想是: 将待排序的元素按照大小顺序, 依次插入到一个已经排好序的数组之中, 直到所有的元素都插入进去.
由于直接插入排序每次只移动一个元素的位置, 并不会改变值相同的元素之间的排序, 因此它是一种稳定排序.
1 | /** 4、直接插入排序 **/ |
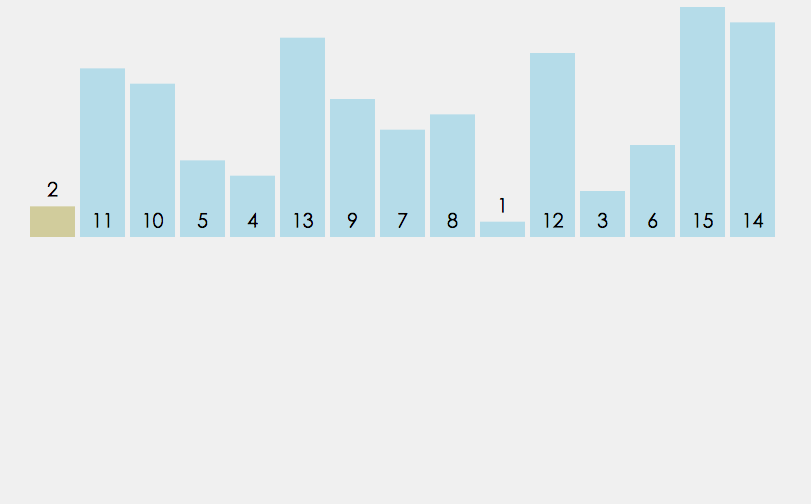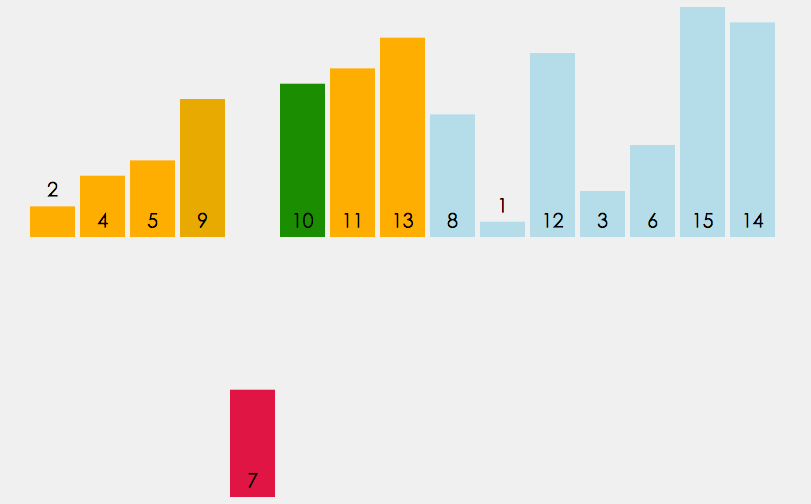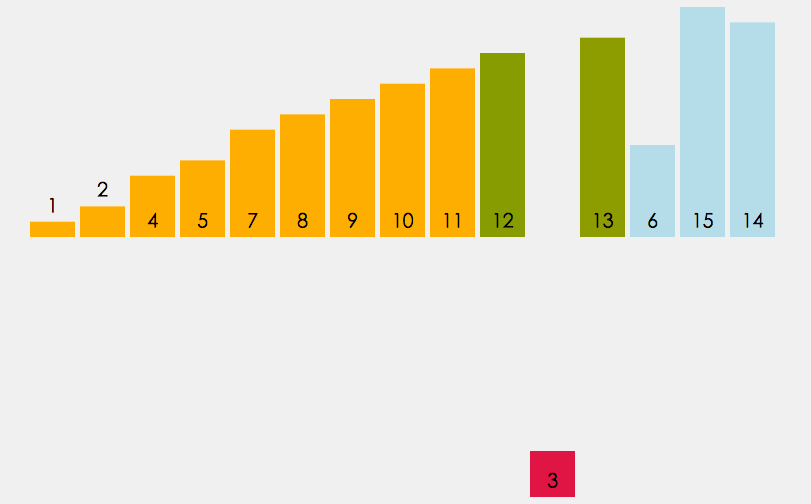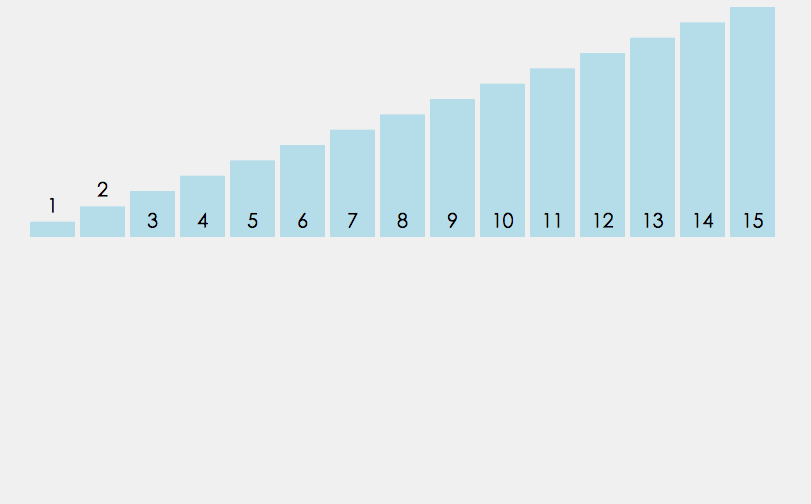
折半插入排序是直接插入排序的升级版. 鉴于插入排序第一部分为已排好序的数组, 我们不必按顺序依次寻找插入点, 只需比较它们的中间值与待插入元素的大小即可.
说白一点就是从第二个数开始向前比较,前面的数(已经排好序)分成两半,找到中间的数,比较大小,然后在向中间循环,一直找到介于两者之间的,然后把之后的后移,将此值插入到后移留出来的位置。
和直接插入法相比,少了一半数据量的对比。
算法基本思想是:
1 | /** 5、折半插入排序 **/ |
希尔排序也称缩小增量排序, 它是直接插入排序的另外一个升级版, 实质就是分组插入排序. 希尔排序以其设计者希尔(Donald Shell)的名字命名, 并于1959年公布.
算法的基本思想:
示意图: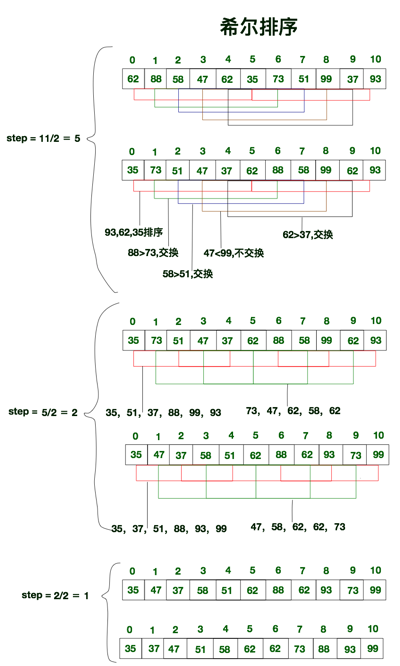
可见, 希尔排序实际上就是不断的进行直接插入排序, 分组是为了先将局部元素有序化. 因为直接插入排序在元素基本有序的状态下, 效率非常高. 而希尔排序呢, 通过先分组后排序的方式, 制造了直接插入排序高效运行的场景. 因此希尔排序效率更高.
1 | /** 6、希尔排序 **/ |
这是一种使用非常广泛的排序,典型的代表就是Chrome的v8引擎为了高效排序, 在排序数据超过了10条时, 便会采用快速排序. 对于10条及以下的数据采用的便是插入排序
快速排序”的思想很简单,整个排序过程只需要三步:
(1)在数据集之中,选择一个元素作为”基准”(pivot)。
(2)所有小于”基准”的元素,都移到”基准”的左边;所有大于”基准”的元素,都移到”基准”的右边。
(3)对”基准”左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
1 | /** 7、快速排序 **/ |

归并排序建立在归并操作之上, 它采取分而治之的思想, 将数组拆分为两个子数组, 分别排序, 最后才将两个子数组合并; 拆分的两个子数组, 再继续递归拆分为更小的子数组, 进而分别排序, 直到数组长度为1, 直接返回该数组为止.
1 | /** 8、归并排序 **/ |

计数排序利用了一个特性, 对于数组的某个元素, 一旦知道了有多少个其它元素比它小(假设为m个), 那么就可以确定出该元素的正确位置(第m+1位)
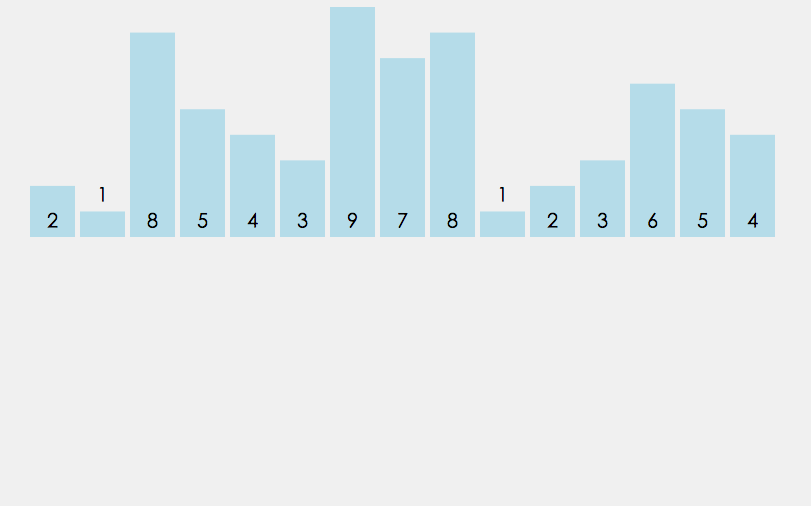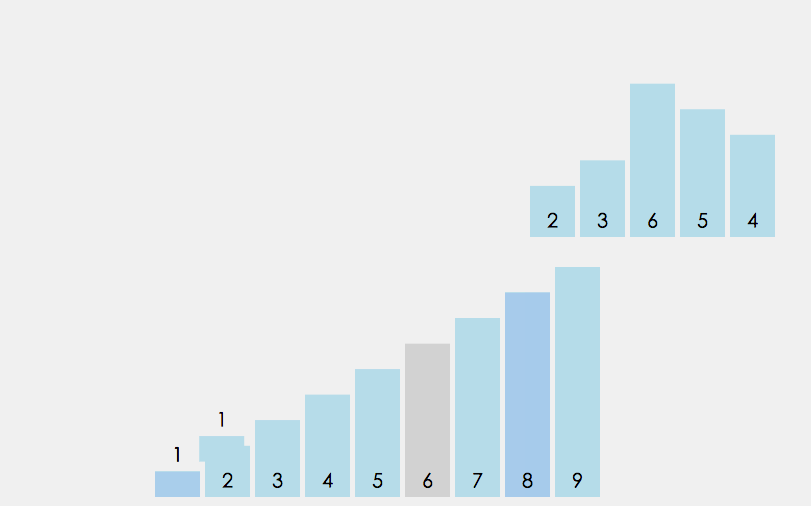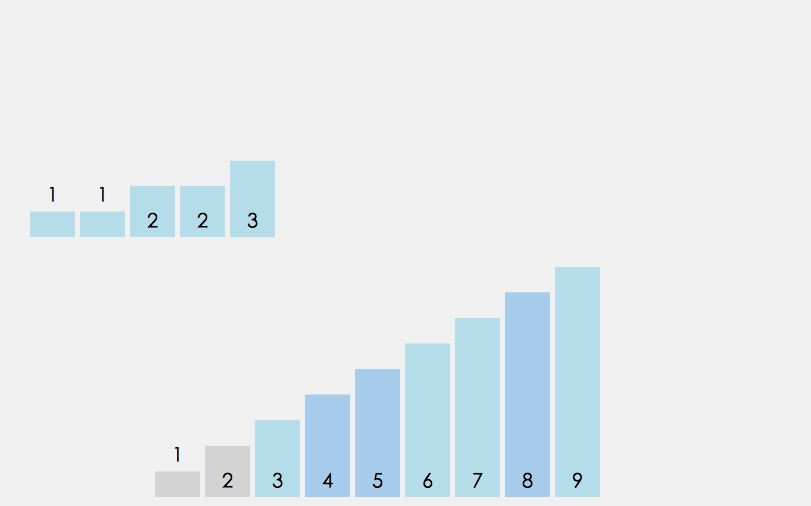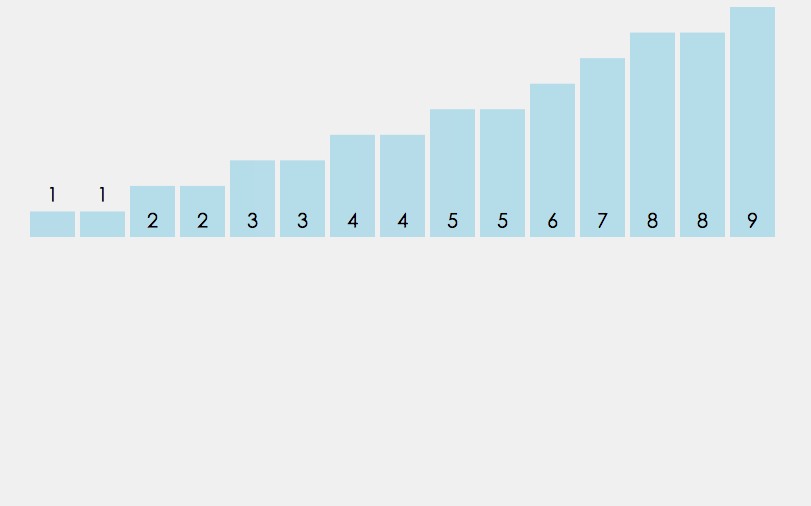
桶排序即所谓的箱排序, 它是将数组分配到有限数量的桶子里. 每个桶里再各自排序(因此有可能使用别的排序算法或以递归方式继续桶排序). 当每个桶里的元素个数趋于一致时, 桶排序只需花费O(n)的时间. 桶排序通过空间换时间的方式提高了效率, 因此它需要额外的存储空间(即桶的空间).
基数排序源于老式穿孔机, 排序器每次只能看到一个列. 它是基于元素值的每个位上的字符来排序的. 对于数字而言就是分别基于个位, 十位, 百位 或千位等等数字来排序. (不明白不要紧, 我也不懂, 请接着往下读)